

The preservationists: Meet the data collectors racing to save the web
A quarter of the internet has already disappeared. From grassroots archivists to the Internet Archive's 866 billion-page vault, meet the guardians of our digital memory.

In the flickering glow of a screen, a digital ghost is fading. A government dataset, available yesterday, returns a 404 error today. A favorite blog post, bookmarked last week, now leads to a parked domain.
This isn't science fiction; it's the quiet, pervasive new reality of the digital age. According to research from the Pew Research Center, a staggering 25% of web pages existing between 2013 and 2023 have simply vanished. The web, our sprawling, vibrant repository of knowledge and culture, is built on shifting sands.
Yet, as the digital tide washes away swathes of our collective memory, a determined movement is fighting back. They are the self-preservationists: a diverse coalition of archivists, librarians, technologists, researchers, business compliance officers, and concerned individuals refusing to accept the ephemerality of the digital world.
From the monumental server racks of the Internet Archive to the focused efforts of Harvard Law School's Library Innovation Lab, from grassroots community projects capturing local histories to individuals taking steps to save content in durable formats, a race is underway to save the web from itself.
"More and more of our intellectual endeavors... exist only in a digital environment," explains Mark Graham, director of the Internet Archive's indispensable Wayback Machine. "That environment is inherently fragile."
The story of web preservation in 2025 is one of resilience, innovation, and a growing understanding that if something digital is worth keeping, it's worth saving—securely and accessibly—before it vanishes forever.
The Digital Erosion Crisis
The web is vanishing beneath our feet. What appears stable is, in reality, built on shifting digital sands. The statistics paint a sobering picture: according to Pew Research Center, 38% of web pages from 2013 are now inaccessible. Even recent content isn't immune; 8% of pages published in 2023 vanished within the same year.
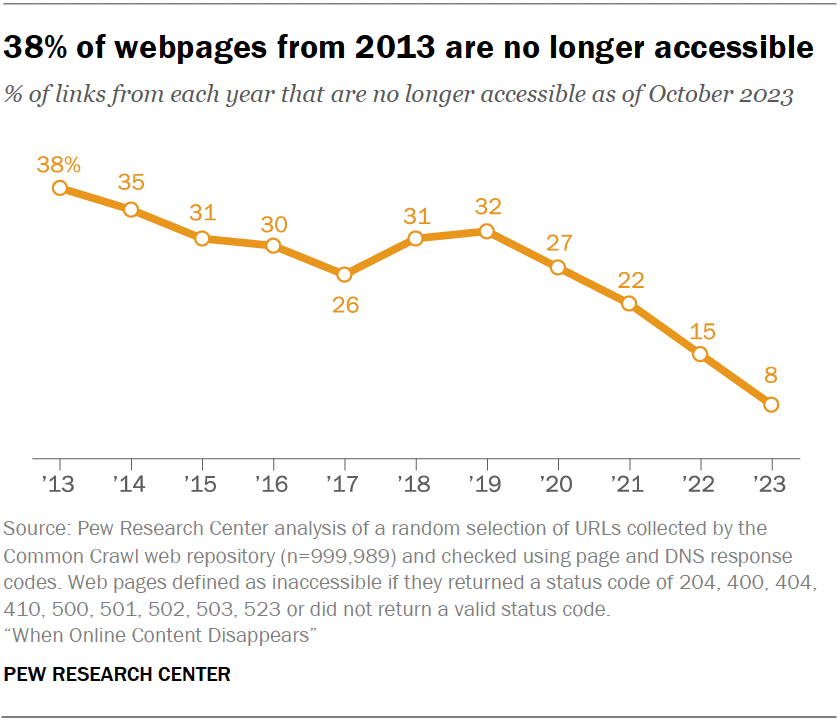
Source: Pew Research Center, When Content Disappears, May 2024
This digital erosion affects critical information infrastructure. One in five government websites contains broken links, while Pew Research Center found over half of Wikipedia articles have broken links in their references. In other words, the foundation of evidence supporting online information is slowly disintegrating. "The risks are manifold... institutions fail, or companies go out of business," notes Mark Graham.
The causes are both technical and institutional. Link rot—the decay of hyperlinks—is endemic. Websites restructure, domains expire, companies fold, platforms pivot. Hardware and software obsolescence renders content unreadable.
Institutional decisions accelerate this loss. Cost-cutting, rebranding, legal concerns, or political expediency lead to content removal. The 2025 US presidential transition saw thousands of datasets disappear from Data.gov almost overnight. Walled gardens and proprietary platforms create digital silos where content is held captive, prone to disappearing when the platform changes course.
This digital impermanence is undermining accountability, hinders research, and fragments cultural memory.
The Preservation Vanguard: Major Players and Initiatives
At the forefront of the battle against digital amnesia stands the Internet Archive, a non-profit digital library founded in 1996. By 2025, it had preserved an astounding 866 billion web pages, 44 million books, and countless other digital artifacts. Its Wayback Machine relentlessly crawls the web, capturing snapshots of websites over time, making them available free of charge. "When we then went and looked at how many of those URLs were available in the Wayback Machine, we found that two-thirds of those were available," explains Graham, highlighting its success in preserving otherwise lost content.

Mark Graham, Internet Archive - Source: Wikimedia Commons, Creative Commons Attribution 2.0
A key initiative is the End of Term Web Archive, which snapshots U.S. government websites, many of whose pages are deleted during presidential transitions. The 2024/2025 crawl collected over 500 terabytes, including more than 100 million unique web pages, further secured on decentralized networks like Filecoin as part of its Democracy's Library project.
Academic institutions contribute crucial expertise. Harvard Law School's Library Innovation Lab complements the Internet Archive by creating a "data vault" for federal datasets. Following the 2025 transition, it released a 16-terabyte collection of over 311,000 datasets from Data.gov, providing open-source tools for replication. Elsewhere, national libraries like the U.S. Library of Congress and the UK Web Archive also play vital roles, archiving government sites, news, and national domains.
Collaborative efforts amplify these strengths. The Internet Archive's Community Webs program empowers over 200 smaller cultural heritage organizations to preserve their own, local digital histories, diversifying the archival record. As one participant, Raíces Cultural Center, notes, the program fosters "community identity... and sharing untold or undertold stories." Meanwhile, coalitions like the Data Rescue Project, run by university librarians, track data takedowns and coordinate preservation responses. Individuals also contribute; as Gary Price explained in Online Searcher, anyone can add websites to the Internet Archive, democratizing preservation.
Motivations: Why Save the Web?
You don’t have to be a hoarder to want to preserve digital data. The race to save the web is driven by a complex interplay of motivations spanning commercial interests, cultural imperatives, academic needs, and legal requirements.
For businesses, data archival is a strategic necessity. Regulatory frameworks like GDPR, CCPA, and the Sarbanes-Oxley Act mandate retention and accessibility, with non-compliance carrying severe penalties. Robust archiving is essential for risk management and business continuity across industries like healthcare, finance, and e-commerce. The enterprise information archiving market, projected to exceed $10.5 billion in 2025 according to The Business Research Company, underscores this commercial reality.
Cultural and historical imperatives provide a powerful motivation. "Historians of the future may struggle to understand fully how we lived our lives in the early 21st Century," a recent BBC News article warned. Institutions are working to ensure our digital present doesn't become a historical black hole, striving to capture diverse voices and recognizing that, without deliberate effort, the digital narratives of marginalized communities are particularly vulnerable.
Academia relies heavily on a stable digital record. Researchers need persistent access to cited sources to verify findings and build upon previous work. The disintegration of online references undermines scholarly integrity. Historians and social scientists require preserved digital artifacts—websites, social media data—to analyze contemporary society. Legal systems increasingly intersect with the digital realm. Court cases may hinge on archived emails or website content, while government accountability relies on preserved official records.
Underpinning these institutional drivers is a growing focus on personal digital agency—a desire to reclaim control in the face of ephemeral platforms. This reflects an unease with entrusting personal digital histories to transient third-party services. Individuals are exploring ways to save content in durable, accessible formats they control, such as using tools to capture web pages as Markdown files. A growing number of web user seems driven by the principle that content worth finding is often worth preserving.
Hurdles on the Path: Challenges and Controversies
Despite the growing momentum, the path to comprehensive web preservation is fraught with significant hurdles.
Legal battles cast a long shadow. Copyright law, designed for physical media, sometimes clashes with mass web crawling. Publishers have launched lawsuits against archives like the Internet Archive, arguing infringement. While archives invoke fair use defenses, the legal landscape remains uncertain and costly. The "right to be forgotten," established in some jurisdictions, introduces further complexity, pitting individual privacy against the historical record.
Wayback Machine, Internet Archive
Resource constraints perpetually challenge preservation. The scale of the web vastly outstrips available funding. Building and maintaining the technical infrastructure requires substantial, ongoing investment. Specialized expertise in web archiving and digital forensics remains scarce.
Selection bias inevitably shapes what gets saved. Who decides which websites or communities are worthy of preservation? Institutional archives may inadvertently perpetuate historical biases, underrepresenting content from marginalized communities or non-mainstream platforms. Ethical considerations, particularly around preserving sensitive personal information captured without explicit consent, remain paramount.
Technical difficulties abound. The modern web is dynamic, interactive, and often hidden behind logins. Capturing the full functionality of complex web applications is notoriously difficult. Format obsolescence remains a constant threat, requiring ongoing migration and emulation strategies.
Charting the Future: Innovation and Uncertainty
The future of web preservation is being actively shaped by technological innovation, evolving policies, and the shifting dynamics between institutional and individual efforts.
Decentralized technologies offer a paradigm shift. Projects leveraging networks like Filecoin to store archived data across multiple nodes promise greater resilience against single points of failure. Artificial intelligence is poised to revolutionize preservation workflows, assisting in identifying at-risk content, prioritizing crawling, generating metadata, and enhancing searchability.
Policy and legal frameworks remain critical battlegrounds. Calls for mandated archiving, particularly for government data, may gain traction. International collaboration could lead to more standardized practices. However, these efforts could continue to clash with commercial interests and privacy concerns. The role of dominant tech platforms remains uncertain, with tension between proprietary platform archives and independent, public-interest archiving likely to grow.
Finding sustainable funding models beyond non-profit donations and grants remains crucial. The future likely involves a deeper integration of institutional and personal preservation efforts, connecting large repositories with individual actions facilitated by user-controlled formats and tools, embodying a "file over app" philosophy for digital longevity.
Guardians of Digital Memory
The web, our sprawling, collective consciousness, is surprisingly ephemeral. As links decay and platforms vanish, the self-preservationists—institutional and individual—stand as guardians against a rising tide of digital amnesia. From the monumental efforts of the Internet Archive to the individual saving crucial articles in durable formats, the motivations are shared: a refusal to let our digital heritage dissolve.
The challenge is immense. Yet, the preservation movement is growing, driven by the understanding that access to information—past and present—is fundamental.
"Web archiving is more than just preserving history—it’s about ensuring access to information for future generations," observes Mark Graham. This task falls not only to dedicated archivists but to all users of the web. Supporting preservation organizations, advocating for responsible data policies, and adopting personal preservation habits are all part of the solution.
The race against digital forgetting requires collective vigilance. By embracing both institutional scale and individual agency, we can strive to ensure that the vibrant, complex, and essential record of our digital lives endures.
 |
|
The digital world was never built to last forever — but our responsibility is to decide what deserves to endure. From global institutions to individuals with a bookmark habit, every effort matters in fighting digital amnesia. The question is: what will you choose to preserve for tomorrow’s web?